Node.js 问答
Node 中间件
中间件概念
在 NodeJS 中,中间件主要是指封装所有 Http 请求细节处理的方法。一次 Http 请求通常包含很多工作,如记录日志、ip 过滤、查询字符串、请求体解析、Cookie 处理、权限验证、参数验证、异常处理等,但对于 Web 应用而言,并不希望接触到这么多细节性的处理,因此引入中间件来简化和隔离这些基础设施与业务逻辑之间的细节,让开发者能够关注在业务的开发上,以达到提升开发效率的目的。
中间件的行为比较类似 Java 中过滤器的工作原理,就是在进入具体的业务处理之前,先让过滤器处理。它的工作模型下图所示。 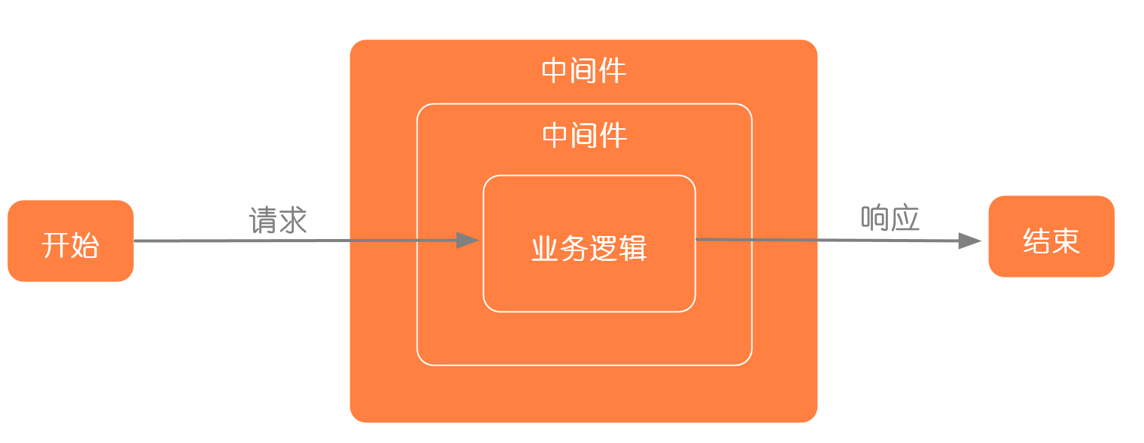
中间件工作模型
中间件机制核心实现
中间件是从 Http 请求发起到响应结束过程中的处理方法,通常需要对请求和响应进行处理,因此一个基本的中间件的形式如下:
const middleware = (req, res, next) => {
// TODO
next();
};
const middleware = (req, res, next) => {
// TODO
next();
};
以下通过两种方式的中间件机制的实现来理解中间件是如何工作的。
方式一
如下定义三个简单的中间件:
const middleware1 = (req, res, next) => {
console.log('middleware1 start');
next();
};
const middleware2 = (req, res, next) => {
console.log('middleware2 start');
next();
};
const middleware3 = (req, res, next) => {
console.log('middleware3 start');
next();
};
const middleware1 = (req, res, next) => {
console.log('middleware1 start');
next();
};
const middleware2 = (req, res, next) => {
console.log('middleware2 start');
next();
};
const middleware3 = (req, res, next) => {
console.log('middleware3 start');
next();
};
通过递归的形式,将后续中间件的执行方法传递给当前中间件,在当前中间件执行结束,通过调用 next()方法执行后续中间件的调用。
// 中间件数组
const middlewares = [middleware1, middleware2, middleware3];
function run(req, res) {
const next = () => {
// 获取中间件数组中第一个中间件
const middleware = middlewares.shift();
if (middleware) {
middleware(req, res, next);
}
};
next();
}
run(); // 模拟一次请求发起
// 中间件数组
const middlewares = [middleware1, middleware2, middleware3];
function run(req, res) {
const next = () => {
// 获取中间件数组中第一个中间件
const middleware = middlewares.shift();
if (middleware) {
middleware(req, res, next);
}
};
next();
}
run(); // 模拟一次请求发起
执行以上代码,可以看到如下结果:
// middleware1 start
// middleware2 start
// middleware3 start
// middleware1 start
// middleware2 start
// middleware3 start
如果中间件中有异步操作,需要在异步操作的流程结束后再调用 next()方法,否则中间件不能按顺序执行。改写 middleware2 中间件:
const middleware2 = (req, res, next) => {
console.log('middleware2 start');
new Promise((resolve) => {
setTimeout(() => resolve(), 1000);
}).then(() => {
next();
});
};
const middleware2 = (req, res, next) => {
console.log('middleware2 start');
new Promise((resolve) => {
setTimeout(() => resolve(), 1000);
}).then(() => {
next();
});
};
执行结果与之前一致,不过 middleware3 会在 middleware2 异步完成后执行。
方式二
有些中间件不止需要在业务处理前执行,还需要在业务处理后执行,比如统计时间的日志中间件。在方式一情况下,无法在 next()为异步操作时再将当前中间件的其他代码作为回调执行。因此可以将 next()方法的后续操作封装成一个 Promise 对象,中间件内部就可以使用 next.then()形式完成业务处理结束后的回调。改写 run()方法如下:
function run(req, res) {
const next = () => {
const middleware = middlewares.shift();
if (middleware) {
// 将middleware(req, res, next)包装为Promise对象
return Promise.resolve(middleware(req, res, next));
}
};
next();
}
function run(req, res) {
const next = () => {
const middleware = middlewares.shift();
if (middleware) {
// 将middleware(req, res, next)包装为Promise对象
return Promise.resolve(middleware(req, res, next));
}
};
next();
}
中间件的调用方式需改写为:
const middleware1 = (req, res, next) => {
console.log('middleware1 start');
// 所有的中间件都应返回一个Promise对象
// Promise.resolve()方法接收中间件返回的Promise对象,供下层中间件异步控制
return next().then(() => {
console.log('middleware1 end');
});
};
const middleware1 = (req, res, next) => {
console.log('middleware1 start');
// 所有的中间件都应返回一个Promise对象
// Promise.resolve()方法接收中间件返回的Promise对象,供下层中间件异步控制
return next().then(() => {
console.log('middleware1 end');
});
};
得益于 async 函数的自动异步流程控制,中间件也可以用如下方式来实现:
// async函数自动返回Promise对象
const middleware2 = async (req, res, next) => {
console.log('middleware2 start');
await new Promise((resolve) => {
setTimeout(() => resolve(), 1000);
});
await next();
console.log('middleware2 end');
};
const middleware3 = async (req, res, next) => {
console.log('middleware3 start');
await next();
console.log('middleware3 end');
};
// async函数自动返回Promise对象
const middleware2 = async (req, res, next) => {
console.log('middleware2 start');
await new Promise((resolve) => {
setTimeout(() => resolve(), 1000);
});
await next();
console.log('middleware2 end');
};
const middleware3 = async (req, res, next) => {
console.log('middleware3 start');
await next();
console.log('middleware3 end');
};
以上描述了中间件机制中多个异步中间件的调用流程,实际中间件机制的实现还需要考虑异常处理、路由等。
在 express 框架中,中间件的实现方式为方式一,并且全局中间件和内置路由中间件中根据请求路径定义的中间件共同作用,不过无法在业务处理结束后再调用当前中间件中的代码。
koa2 框架中中间件的实现方式为方式二,将 next()方法返回值封装成一个 Promise,便于后续中间件的异步流程控制,实现了 koa2 框架提出的洋葱圈模型,即每一层中间件相当于一个球面,当贯穿整个模型时,实际上每一个球面会穿透两次。
koa2 中间件洋葱圈模型
koa2 框架的中间件机制实现得非常简洁和优雅,这里学习一下框架中组合多个中间件的核心代码。
function compose(middleware) {
if (!Array.isArray(middleware))
throw new TypeError('Middleware stack must be an array!');
for (const fn of middleware) {
if (typeof fn !== 'function')
throw new TypeError('Middleware must be composed of functions!');
}
return function (context, next) {
let index = -1;
return dispatch(0);
function dispatch(i) {
// index会在next()方法调用后累加,防止next()方法重复调用
if (i <= index)
return Promise.reject(
new Error('next() called multiple times')
);
index = i;
let fn = middleware[i];
if (i === middleware.length) fn = next;
if (!fn) return Promise.resolve();
try {
// 核心代码
// 包装next()方法返回值为Promise对象
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
// 遇到异常中断后续中间件的调用
return Promise.reject(err);
}
}
};
}
function compose(middleware) {
if (!Array.isArray(middleware))
throw new TypeError('Middleware stack must be an array!');
for (const fn of middleware) {
if (typeof fn !== 'function')
throw new TypeError('Middleware must be composed of functions!');
}
return function (context, next) {
let index = -1;
return dispatch(0);
function dispatch(i) {
// index会在next()方法调用后累加,防止next()方法重复调用
if (i <= index)
return Promise.reject(
new Error('next() called multiple times')
);
index = i;
let fn = middleware[i];
if (i === middleware.length) fn = next;
if (!fn) return Promise.resolve();
try {
// 核心代码
// 包装next()方法返回值为Promise对象
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
// 遇到异常中断后续中间件的调用
return Promise.reject(err);
}
}
};
}
node.js 中 require('xxx') 是从哪里导入的
require 函数可以导入模块、JSON 文件、本地文件。模块可以通过一个相对路径从 node_modules、本地模块、JSON 文件中导出,该路径将针对__dirname 变量(如果已定义)或者当前工作目录。
node.js 中 事件循环 和 浏览器事件循环的区别
1. 任务队列
浏览器环境
浏览器环境下的 异步任务 分为 宏任务(macroTask) 和 微任务(microTask):
- 宏任务(macroTask):script 中代码、setTimeout、setInterval、I/O、UI render;
- 微任务(microTask): Promise、Object.observe、MutationObserver。
当满足执行条件时,宏任务(macroTask) 和 微任务(microTask) 会各自被放入对应的队列:宏队列(Macrotask Queue) 和 微队列(Microtask Queue) 中等待执行。
Node 环境
在 Node 环境中 任务类型 相对就比浏览器环境下要复杂一些:
- microTask:微任务;
- nextTick:process.nextTick;
- timers:执行满足条件的 setTimeout 、setInterval 回调;
- I/O callbacks:是否有已完成的 I/O 操作的回调函数,来自上一轮的 poll 残留;
- poll:等待还没完成的 I/O 事件,会因 timers 和超时时间等结束等待;可忽略
- check:执行 setImmediate 的回调;
- close callbacks:关闭所有的 closing handles ,一些 onclose 事件;
- idle/prepare 等等:可忽略。
因此,也就产生了执行事件循环相应的任务队列 Timers Queue、I/O Queue、Check Queue 和 Close Queue。
2. 执行过程
浏览器环境
- 执行完主执行线程中的任务;
- 取出 Microtask Queue 中任务执行直到清空;
- 取出 Macrotask Queue 中一个任务执行;
- 重复 2 和 3 。
需要 注意 的是:
- 在浏览器页面中可以认为初始执行线程中没有代码,每一个中的代码是一个独立的 task ,即会执行完前面的中创建的 microTask 再执行后面的
Macrotask中的同步代码; - 如果 microTask 一直被添加,则会继续执行 microTask ,“卡死” macroTask;
- 部分版本浏览器有执行顺序与上述不符的情况,可能是不符合标准或 js 与 html 部分标准冲突;
- Promise 的 then 和 catch 才是 microTask ,本身的内部代码不是;
- 个别浏览器独有 API 未列出。
Node 环境
循环之前
在进入第一次循环之前,会先进行如下操作:
- 同步任务;
- 发出异步请求;
- 规划定时器生效的时间;
- 执行 process.nextTick()。
开始循环
循环中进行的操作:
- 清空当前循环内的 Timers Queue,清空 NextTick Queue,清空 Microtask Queue;
- 清空当前循环内的 I/O Queue,清空 NextTick Queue,清空 Microtask Queue;
- 清空当前循环内的 Check Queue,清空 NextTick Queue,清空 Microtask Queue;
- 清空当前循环内的 Close Queue,清空 NextTick Queue,清空 Microtask Queue;
- 进入下轮循环。
可以看出,nextTick 优先级比 Promise 等 microTask 高,setTimeout 和 setInterval 优先级比 setImmediate 高。
在整个过程中,需要 注意 的是:
- 如果在 timers 阶段执行时创建了 setImmediate 则会在此轮循环的 check 阶段执行,如果在 timers 阶段创建了 setTimeout,由于 timers 已取出完毕,则会进入下轮循环,check 阶段创建 timers 任务同理;
- setTimeout 优先级比 setImmediate 高,但是由于 setTimeout(fn,0)的真正延迟不可能完全为 0 秒,可能出现先创建的 setTimeout(fn,0)而比 setImmediate 的回调后执行的情况。
node.js 中 多进程如何创建子进程
node.js 中 多进程如何创建子进程
hild_process 模块赋予了node可以随意创建子进程的能力 ,它提供了4个方法用于创建子进程:
- spawn(): 启动一个子进程来执行命令
- exec: 启动一个子进程来执行命令,与spawn不同的是其接口不同,他有一个回掉函数来获知子进程的状况。
- execFile(): 启动一个子进程来执行可执行文件。
- fork(): 与spawn()类似,不同点在于它创建Node的子进程只需指定要执行的JavaScript文件模块即可。
spawn()与exec()、execFile()的不同点:
- 后两者创建时可以指定timeout属性设置超时时间,一旦创建的进程运行超过设定的时间将会被杀死
exec()与execFile()的不同点:
- exec()适合执行已有的命令,execFile()适合执行文件。
这里我们以一个寻常命令为例,node worker.js分别用上述4种方法实现,如下所示
var cp = require('child_process');
//spawn
cp.spawn('node', ['worker.js']);
//exec
cp.exec('node worker.js', function (err, stdout, stderr) {
// some code
});
//execFile
cp.execFile('worker.js', function (err, stdout, stderr) {
// some code
});
//fork
cp.fork('./worker.js');
var cp = require('child_process');
//spawn
cp.spawn('node', ['worker.js']);
//exec
cp.exec('node worker.js', function (err, stdout, stderr) {
// some code
});
//execFile
cp.execFile('worker.js', function (err, stdout, stderr) {
// some code
});
//fork
cp.fork('./worker.js');

如果是JavaScript文件通过execFile()运行,它的首行内容必须添加如下代码
#!/usr/bin/env node
#!/usr/bin/env node
尽管4种创建子进程的方式有些差别,但事实上后面3种方法都是spawn()的延伸应用
请介绍一下 require 的模块加载机制
- 计算模块绝对路径;
- 如果缓存中有该模块,则从缓存中取出该模块;
- 按优先级依次寻找并编译执行模块,将模块推入缓存(require.cache)中;
- 输出模块的exports属性;
Node 中的内存泄露问题和解决方案:
内存泄露原因
- 全局变量:全局变量挂在 root 对象上,不会被清除掉;
- 闭包:如果闭包未释放,就会导致内存泄露;
- 事件监听:对同一个事件重复监听,忘记移除(removeListener),将造成内存泄露。
解决方案:
- 最容易出现也是最难排查的就是事件监听造成的内存泄露,所以事件监听这块需要格外注意小心使用。
- 如果出现了内存泄露问题,需要检测内存使用情况,对内存泄露的位置进行定位,然后对对应的内存泄露代码进行修复。
简单介绍一下 IPC
IPC(Inner-Process Communication)又称进程间通信技术,是用于 Node 内部父子进程之间进行通信的方法。
Node 的 IPC 是通过不同平台的管道技术实现的,特点是本地网络通信,速度快,效率高。
Node 在启动子进程的时候,主进程先建立 IPC 通道,然后将 IPC 通道的 fd(文件描述符)通过环境变量(NODE_CHANNEL_FD)的方式传递给子进程,然后子进程通过 fd 与 父进程建立 IPC 连接。
什么是守护进程?Node 如何实现守护进程?
守护进程是不依赖终端(tty)的进程,不会因为用户退出终端而停止运行的进程。
Node 实现守护进程的思路:
- 创建一个进程 A;
- 在进程 A 中创建进程 B,可以使用child_process.fork或者其他方法;
- 启动子进程时,设置detached属性为 true,保证子进程在父进程退出后继续运行;
- 进程 A 退出,进程 B 由 init 进程接管。此时进程 B 为守护进程。
简单介绍一下 Buffer
Buffer 是 Node 中用于处理二进制数据的类,其中与 IO 相关的操作(网络/文件等)均基于 Buffer。Buffer 类的实例非常类似于整数数组,但其大小是固定不变的,并且其内存在 V8 堆栈外分配原始内存空间。
Buffer 类的实例创建之后,其所占用的内存大小就不能再进行调整。