正则表达式
概述
什么是正则表达式
正则表达式( Regular Expression )是用于匹配字符串中字符组合的模式。在 JavaScript 中,正则表达式也 是对象
正则表通常被用来检索、替换那些符合某个模式(规则)的文本,例如验证表单:用户名表单只能输入英文字 母、数字或者下划线, 昵称输入框中可以输入中文(匹配)。此外,正则表达式还常用于过滤掉页面内容中的一 些敏感词(替换),或**从字符串中获取我们想要的特定部分(提取)**等
特点
- 灵活性、逻辑性和功能性非常的强。
- 可以迅速地用极简单的方式达到字符串的复杂控制。
- 对于刚接触的人来说,比较晦涩难懂。比如: ^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$
- 实际开发,一般都是直接复制写好的正则表达式. 但是要求会使用正则表达式并且根据实际情况修改正则表达 式. 比如用户名: /^[a-z0-9_-]{3,16}$/
在 JS 中的使用:
2.1 创建
在 JavaScript 中,可以通过两种方式创建一个正则表达式。
通过调用
RegExp对象的构造函数创建通过字面量创建
// 第一种
var regexp = new RegExp(/123/);
var regexp = new RegExp("\\d+");
console.log(regexp);
// 第二种
var rg = /123/;
console.log(rg);
// 第一种
var regexp = new RegExp(/123/);
var regexp = new RegExp("\\d+");
console.log(regexp);
// 第二种
var rg = /123/;
console.log(rg);
2.2 正则表达式由两部分组成
- 元字符
- 修饰符
2.3 test() 方法
test() 正则对象方法,用于检测字符串是否符合该规则,该对象会返回 true 或 false,其参数是测试字符串
regexObj.test(str)
- regexObj 是写的正则表达式
- str 我们要测试的文本
- 就是检测 str 文本是否符合我们写的正则表达式规范.
var rg = /123/;
console.log(rg.test(123)); // true
console.log(rg.test(1234)); // true
console.log(rg.test(4123)); // true
console.log(rg.test("abc")); // false
// 只要里面有 123 就算字符串符合规则
var rg = /123/;
console.log(rg.test(123)); // true
console.log(rg.test(1234)); // true
console.log(rg.test(4123)); // true
console.log(rg.test("abc")); // false
// 只要里面有 123 就算字符串符合规则
/* 常用元字符*/
//=> 1.量词元字符: 设置出现的次数
* 零到多次
+ 一到多次
? 零或者一次
{n} 出现n次
{n,} 出现 n 到多次
{n,m} 出现 n 到 m次
//=> 2. 特殊元字符: 单个或者组合在一起代表特殊的含义
\ 转义字符(普通->特殊 | 特殊->普通)
. 除 \n (换行)以外的任意字符
^ 以哪一个元字符作为开头
$ 以哪一个元字符作为结束
\n 换行符
\d 0 - 9之间的一个数字
\D 非 0 - 9 之间的一个数字
\w 数字 、 字母 、 下划线中的任意一个字符
\W 非 数字 、 字母 、 下划线中的任意一个字符
\s 一个空白字符(包含空格、制表符、换页符等)
\t 一个制表符(一个TAB键:4个空格)
\b 匹配一个单词的边界
x|y x或者y中的一个字符
[xyz] x或者y或者z中的一个字符
[^xyz] 除了x y z以外的字符
[a-z] 指定a-z这个范围中的任意字符
[^a-z] 非 指定a-z这个范围中的任意字符
() 正则中的分组符号
(?:) 只匹配不捕获
(?=) 正向预查
(?!) 负向预查
//=> 3.普通元字符:代表本身含义的
/* 常用元字符*/
//=> 1.量词元字符: 设置出现的次数
* 零到多次
+ 一到多次
? 零或者一次
{n} 出现n次
{n,} 出现 n 到多次
{n,m} 出现 n 到 m次
//=> 2. 特殊元字符: 单个或者组合在一起代表特殊的含义
\ 转义字符(普通->特殊 | 特殊->普通)
. 除 \n (换行)以外的任意字符
^ 以哪一个元字符作为开头
$ 以哪一个元字符作为结束
\n 换行符
\d 0 - 9之间的一个数字
\D 非 0 - 9 之间的一个数字
\w 数字 、 字母 、 下划线中的任意一个字符
\W 非 数字 、 字母 、 下划线中的任意一个字符
\s 一个空白字符(包含空格、制表符、换页符等)
\t 一个制表符(一个TAB键:4个空格)
\b 匹配一个单词的边界
x|y x或者y中的一个字符
[xyz] x或者y或者z中的一个字符
[^xyz] 除了x y z以外的字符
[a-z] 指定a-z这个范围中的任意字符
[^a-z] 非 指定a-z这个范围中的任意字符
() 正则中的分组符号
(?:) 只匹配不捕获
(?=) 正向预查
(?!) 负向预查
//=> 3.普通元字符:代表本身含义的
/* 正则表达式常用的修饰符*/
(i) => 忽略单词大小写匹配;
(m) => 忽略换行匹配;
(g) => 全局匹配;
/* 正则表达式常用的修饰符*/
(i) => 忽略单词大小写匹配;
(m) => 忽略换行匹配;
(g) => 全局匹配;
正则表达式捕获的懒惰性
实现正则捕获的方法
- 正则 RegExp.prototype 上的方法
- exec
- test
- 字符串 String.prototype 上支持正则表达式出来的方法
- replace
- match
- splite
- 。。。
// 实现正则捕获的前提是:当前正则 和 字符串匹配。 如果不匹配 test 的结果就是 false了 怎么捕获
/* exec实现正则的捕获
* 1.捕获到的结果是 null 或者 一个数组。
数字第一项就是本次捕获到的内容
其余项:对应小分组本次单独捕获的内容
index: 当前捕获内容在字符串中的起始索引
input:原始字符串
2. 每执行一次exec, 只能捕获到第一个符合正则规则的,后面字符串若也有符合规则的也不会去捕获。
3. 这就是 正则捕获的懒惰性 => 默认只捕获第一个符合规则的
懒惰性的原因是: 默认情况下 lastIndex(当前正则下一次匹配的起始索引位置) 的值不会被修改,每一次都是从字符串开始位去匹配,所以永远找到的只是第一个
解决办法: 全局修饰符 g
*/
// 实现正则捕获的前提是:当前正则 和 字符串匹配。 如果不匹配 test 的结果就是 false了 怎么捕获
/* exec实现正则的捕获
* 1.捕获到的结果是 null 或者 一个数组。
数字第一项就是本次捕获到的内容
其余项:对应小分组本次单独捕获的内容
index: 当前捕获内容在字符串中的起始索引
input:原始字符串
2. 每执行一次exec, 只能捕获到第一个符合正则规则的,后面字符串若也有符合规则的也不会去捕获。
3. 这就是 正则捕获的懒惰性 => 默认只捕获第一个符合规则的
懒惰性的原因是: 默认情况下 lastIndex(当前正则下一次匹配的起始索引位置) 的值不会被修改,每一次都是从字符串开始位去匹配,所以永远找到的只是第一个
解决办法: 全局修饰符 g
*/
正则表达式的分组捕获和分组引用
// 正则的分组捕获
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(\d|X)$/;
let str = "362321200011164017";
console.log(str.match(reg)); // 或者是 console.log(reg.exec(str))
/* 0: "362321200011164017"
1: "362321"
2: "2000"
3: "11"
4: "16"
5: "1"
6: "7"
第一项: 大正则匹配的结果
其余项: 每一个小分组单独匹配捕获的结果 // 这就是分组捕获
// =》 如果设置了分组(改变优先级),但是分组捕获的时候 不需要单独捕获某一小分组,可以基于 ?:(只匹配不捕获) 来处理
*/
// 正则的分组捕获
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(\d|X)$/;
let str = "362321200011164017";
console.log(str.match(reg)); // 或者是 console.log(reg.exec(str))
/* 0: "362321200011164017"
1: "362321"
2: "2000"
3: "11"
4: "16"
5: "1"
6: "7"
第一项: 大正则匹配的结果
其余项: 每一个小分组单独匹配捕获的结果 // 这就是分组捕获
// =》 如果设置了分组(改变优先级),但是分组捕获的时候 不需要单独捕获某一小分组,可以基于 ?:(只匹配不捕获) 来处理
*/
// => 既要捕获到数字 {数字}, 也要单独的把数字也获取到。 例如:第一次找到 {0} 还需要单独获取 0
let str = "{0}年{1}月{2}日";
let reg = /\{(\d+)\}/;
console.log(str.match(reg));
/*
0: "{0}" // 获取到{数字}
1: "0" // 也获取到 单独的 数字
groups: undefined
index: 0
input: "{0}年{1}月{2}日"
length: 2
*/
let str = "{0}年{1}月{2}日";
let reg = /\{(\d+)\}/g;
console.log(str.match(reg));
/*
0: "{0}"
1: "{1}"
2: "{2}"
*/
// 如果 上面了 正则 设置了 g 之后, mtach 获取不到小分组的内容 只能获取大分组(大正则)的内容
// 为了解决 match 方法的问题g
let str = "{0}年{1}月{2}日";
let reg = /\{(\d+)\}/g;
// aryBig 存放大分组的内容 arySmall 存放小分组的内容 res=reg.exec(str) 当res为null时没有匹配该正则的了
let aryBig = [],
arySmall = [],
res = reg.exec(str);
while (res) {
let [big, small] = res;
aryBig.push(big);
arySmall.push(small);
res = reg.exec(str);
}
// 在 while 语句 判断 res 是否为null 来进行多次
// => 既要捕获到数字 {数字}, 也要单独的把数字也获取到。 例如:第一次找到 {0} 还需要单独获取 0
let str = "{0}年{1}月{2}日";
let reg = /\{(\d+)\}/;
console.log(str.match(reg));
/*
0: "{0}" // 获取到{数字}
1: "0" // 也获取到 单独的 数字
groups: undefined
index: 0
input: "{0}年{1}月{2}日"
length: 2
*/
let str = "{0}年{1}月{2}日";
let reg = /\{(\d+)\}/g;
console.log(str.match(reg));
/*
0: "{0}"
1: "{1}"
2: "{2}"
*/
// 如果 上面了 正则 设置了 g 之后, mtach 获取不到小分组的内容 只能获取大分组(大正则)的内容
// 为了解决 match 方法的问题g
let str = "{0}年{1}月{2}日";
let reg = /\{(\d+)\}/g;
// aryBig 存放大分组的内容 arySmall 存放小分组的内容 res=reg.exec(str) 当res为null时没有匹配该正则的了
let aryBig = [],
arySmall = [],
res = reg.exec(str);
while (res) {
let [big, small] = res;
aryBig.push(big);
arySmall.push(small);
res = reg.exec(str);
}
// 在 while 语句 判断 res 是否为null 来进行多次
// 分组的第三个作用: '分组引用'
let str = "book";
let reg = /^[a-zA-Z]([a-zA-Z])\1[a-zA-Z]$/;
//=> 分组引用 就是用过数字 "\数字" 让其代表和对应分组出现一模一样的内容
// 上面正则的解释: \1 代表的就是 出现和 分组1 一模一样的内容
// 如果是 \2 出现和 分组2 一模一样的内容
console.log(reg.test("book")); // true
console.log(reg.test("some")); // false
// 分组的第三个作用: '分组引用'
let str = "book";
let reg = /^[a-zA-Z]([a-zA-Z])\1[a-zA-Z]$/;
//=> 分组引用 就是用过数字 "\数字" 让其代表和对应分组出现一模一样的内容
// 上面正则的解释: \1 代表的就是 出现和 分组1 一模一样的内容
// 如果是 \2 出现和 分组2 一模一样的内容
console.log(reg.test("book")); // true
console.log(reg.test("some")); // false
正则表达式之取消贪婪性
// 正则捕获的贪婪性: 默认情况下,正则捕获的时候是按照当前正则匹配的最长结果来获取的
// 举个例子:
let str = "去年2019今天2020";
let reg = /\d+/g; // \d 代表 0-9的数字 + 代表出现 1-n次
console.log(str.match(reg)); // => ["2019", "2020"]
// 按照逻辑来说 符合这个的规则 不止 2019 和 2020 还有 2 、0、 1、 9、20、201、。。。等等等
// 如何取消 正则的贪婪性
reg = /\d+?/g; // 在量词元字符(+) 后面加 ?。 取消捕获的时候的贪婪性(按照正则匹配的最短结果来获取)
console.log(str.match(reg)); // => ["2", "0", "1", "9", "2", "0", "2", "0"]
// 正则捕获的贪婪性: 默认情况下,正则捕获的时候是按照当前正则匹配的最长结果来获取的
// 举个例子:
let str = "去年2019今天2020";
let reg = /\d+/g; // \d 代表 0-9的数字 + 代表出现 1-n次
console.log(str.match(reg)); // => ["2019", "2020"]
// 按照逻辑来说 符合这个的规则 不止 2019 和 2020 还有 2 、0、 1、 9、20、201、。。。等等等
// 如何取消 正则的贪婪性
reg = /\d+?/g; // 在量词元字符(+) 后面加 ?。 取消捕获的时候的贪婪性(按照正则匹配的最短结果来获取)
console.log(str.match(reg)); // => ["2", "0", "1", "9", "2", "0", "2", "0"]
正则表达式之其他捕获方法(replace)
replace 字符串中实现替换的方法(一般都是伴随着正则一起使用的)
let str = "jinnian@2109|jinnian@2020";
// => 把 jinnian 替换成 中国
str = str.replace(/jinnian/g, "中国");
console.log(str); // => 中国@2019|中国@2020
let str = "jinnian@2109|jinnian@2020";
// => 把 jinnian 替换成 中国
str = str.replace(/jinnian/g, "中国");
console.log(str); // => 中国@2019|中国@2020
// 案例: 把时间字符串进行处理
let time = "2020-05-12"
// 把 字符串变为 2020年08月12日
time = time.replace(/^(\d{4})-(\d{2})-(\d{1,2})$/g, "$1年$2月$3日")
// $1 => RegExp.$1 第一个分组 2020
// $2 => RegExp.$2 第二个分组 08
// $3 => RegExp.$3 第三个分组 12
// 也可以这样处理
time = time.replace(reg, (big, ...arg)=>{
let [$1, $2, $3] = arg
$2.length< 2 ? $2 = "0" + $2 : null
$3.length< 2 ? $2 = "0" + $3 : null
return $1+'年'$2+'月'$3+'日'
})
// 案例: 单词首字母大写
let str = "good good study, day day up!";
let reg = /\b([a-zA-Z])[a-zA-Z]*\b/g
// 回调函数 会被执行6次, 每一次都把正则匹配信息传递给函数
str = str.replace(reg, (...arg)=> {
let [content, $1] = arg
$1 = $1,toUpperCase()
content = content.substring(1)
return $1 + content
})
// Good Good Study, Day Day Up!
// 案例: 把时间字符串进行处理
let time = "2020-05-12"
// 把 字符串变为 2020年08月12日
time = time.replace(/^(\d{4})-(\d{2})-(\d{1,2})$/g, "$1年$2月$3日")
// $1 => RegExp.$1 第一个分组 2020
// $2 => RegExp.$2 第二个分组 08
// $3 => RegExp.$3 第三个分组 12
// 也可以这样处理
time = time.replace(reg, (big, ...arg)=>{
let [$1, $2, $3] = arg
$2.length< 2 ? $2 = "0" + $2 : null
$3.length< 2 ? $2 = "0" + $3 : null
return $1+'年'$2+'月'$3+'日'
})
// 案例: 单词首字母大写
let str = "good good study, day day up!";
let reg = /\b([a-zA-Z])[a-zA-Z]*\b/g
// 回调函数 会被执行6次, 每一次都把正则匹配信息传递给函数
str = str.replace(reg, (...arg)=> {
let [content, $1] = arg
$1 = $1,toUpperCase()
content = content.substring(1)
return $1 + content
})
// Good Good Study, Day Day Up!
正则表达式的特殊字符:
一个正则表达式可以由简单的字符构成,比如 /abc/,也可以是简单和特殊字符的组合,比如 /ab*c/ 。其中 特殊字符也被称为元字符,在正则表达式中是具有特殊意义的专用符号,如 ^ 、$ 、+ 等
3.1 特殊字符非常多,可以参考:
MDN:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions
jQuery 手册:正则表达式部分
正则测试工具: http://tool.oschina.net/regex
3.2 边界符
正则表达式中的边界符(位置符)用来提示字符所处的位置,主要有两个字符。
^ 表示匹配行首的文本(谁开头)
$ 表示匹配行尾的文本(谁结尾)
如果 ^ 和 $ 在一起,表示必须是精确匹配
// 边界符 ^ $
// 正则表达式/ /不需要加引号,不管是数组还是字符串
// ^ 代表必须以 abc 开头的
var rg = /^abc/;
console.log(rg.test("abc")); // true
console.log(rg.test("dabc")); // false
// $ 代表以 abc 结尾的
var rg1 = /abc$/;
console.log(rg1.test("dabc")); // true
// 结合 ^ $ 表示必须是精确匹配 必须是 abc
var rg2 = /^abc$/; //代表只能是 abc
console.log(rg2.test("abc")); // true
console.log(rg2.test("abcabc")); // false
// 边界符 ^ $
// 正则表达式/ /不需要加引号,不管是数组还是字符串
// ^ 代表必须以 abc 开头的
var rg = /^abc/;
console.log(rg.test("abc")); // true
console.log(rg.test("dabc")); // false
// $ 代表以 abc 结尾的
var rg1 = /abc$/;
console.log(rg1.test("dabc")); // true
// 结合 ^ $ 表示必须是精确匹配 必须是 abc
var rg2 = /^abc$/; //代表只能是 abc
console.log(rg2.test("abc")); // true
console.log(rg2.test("abcabc")); // false
3.3 字符类
字符类表示有一系列字符可供选择,只要匹配其中一个就可以了。所有可供选择的字符都放在方括号内
1 [] 方括号
var rg = /[abc]/;
// 只要字符串包含 abc 任意一个字符,都返回 true
console.log(rg.test("andy"));
var rg2 = /^[abc]$/;
// 三选一 只有是a 或者是b 或者是c 这个三个字母才返回 true
console.log(rg2.test("a"));
console.log(rg2.test("b"));
console.log(rg2.test("c"));
// 都是 true
var rg = /[abc]/;
// 只要字符串包含 abc 任意一个字符,都返回 true
console.log(rg.test("andy"));
var rg2 = /^[abc]$/;
// 三选一 只有是a 或者是b 或者是c 这个三个字母才返回 true
console.log(rg2.test("a"));
console.log(rg2.test("b"));
console.log(rg2.test("c"));
// 都是 true
2 [-] 方括号内部 范围符
// [-] 方括号内部的 范围符
var rg3 = /^[a-z]$/;
console.log(rg3.test("f"));
// 方括号内部加上 - 表示范围,这里表示 a 到 z 26个英文字母都可以
// [-] 方括号内部的 范围符
var rg3 = /^[a-z]$/;
console.log(rg3.test("f"));
// 方括号内部加上 - 表示范围,这里表示 a 到 z 26个英文字母都可以
3 [^] 方括号内部 取反符^
// 字符组合
var reg = /^[a-zA-Z]$/;
console.log(reg.test("B"));
// 26个英文字母(大小写)如何一个字母 都返回true
// 如果中括号里面有 ^ 表示取反的意思
var reg2 = /^[^a-zA-Z]$/;
console.log(reg2.test("B")); // false
console.log(reg2.test(2)); // true
// 字符组合
var reg = /^[a-zA-Z]$/;
console.log(reg.test("B"));
// 26个英文字母(大小写)如何一个字母 都返回true
// 如果中括号里面有 ^ 表示取反的意思
var reg2 = /^[^a-zA-Z]$/;
console.log(reg2.test("B")); // false
console.log(reg2.test(2)); // true
方括号内部加上 ^ 表示取反,只要包含方括号内的字符,都返回 false
4 字符组合
// 字符组合
var reg = /^[a-zA-Z1-9]$/;
console.log(reg.test("B"));
// 这里表示包含 a 到 z 的26个英文字母(大小写)和 1 到 9 的数字都可以 都返回true
// 字符组合
var reg = /^[a-zA-Z1-9]$/;
console.log(reg.test("B"));
// 这里表示包含 a 到 z 的26个英文字母(大小写)和 1 到 9 的数字都可以 都返回true
方括号内部可以使用字符组合。
3.4 量词类
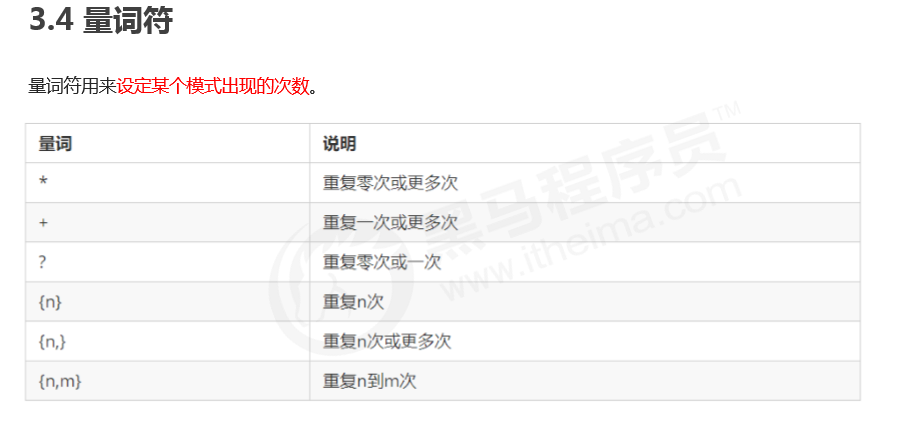
// * 重复零次或更多次
var reg = /^a*$/;
console.log(reg.test(""));
console.log(reg.test("a"));
console.log(reg.test("aaaa"));
// + 至少出现一次或更多次
var reg = /^a+$/;
console.log(reg.test("")); // false
console.log(reg.test("a")); // true
console.log(reg.test("aaaa")); // true
// ? 出现一次或 0次
var reg = /^a?$/;
console.log(reg.test("")); // true
console.log(reg.test("a")); // true
console.log(reg.test("aaaa")); // false
// {n} // 重复 n 次
var reg = /^a{3}$/;
console.log(reg.test("")); // false
console.log(reg.test("a")); // false
console.log(reg.test("aaa")); // true
// {n,} // 重复大于等于n次
var reg = /^a{3,}$/;
console.log(reg.test("")); // false
console.log(reg.test("a")); // fasle
console.log(reg.test("aaa")); // true
console.log(reg.test("aaaa")); // true
// {n,m} 重复大于等于n次 小于等于 m 次
var reg = /^a{2,4}$/;
console.log(reg.test("")); // false
console.log(reg.test("aa")); // true
console.log(reg.test("aaaaa")); // false
// 表单使用的例子
var reg = /^[a-zA-Z0-9_-]{6,16}$/;
console.log(reg.test("andy-red")); // true
console.log(reg.test("andy_red")); // true
console.log(reg.test("andy!007")); // false
// 只能输入 a-z 或者 A-Z 或者 0-9 _ - 并且必须在6位以上和16位一下
// * 重复零次或更多次
var reg = /^a*$/;
console.log(reg.test(""));
console.log(reg.test("a"));
console.log(reg.test("aaaa"));
// + 至少出现一次或更多次
var reg = /^a+$/;
console.log(reg.test("")); // false
console.log(reg.test("a")); // true
console.log(reg.test("aaaa")); // true
// ? 出现一次或 0次
var reg = /^a?$/;
console.log(reg.test("")); // true
console.log(reg.test("a")); // true
console.log(reg.test("aaaa")); // false
// {n} // 重复 n 次
var reg = /^a{3}$/;
console.log(reg.test("")); // false
console.log(reg.test("a")); // false
console.log(reg.test("aaa")); // true
// {n,} // 重复大于等于n次
var reg = /^a{3,}$/;
console.log(reg.test("")); // false
console.log(reg.test("a")); // fasle
console.log(reg.test("aaa")); // true
console.log(reg.test("aaaa")); // true
// {n,m} 重复大于等于n次 小于等于 m 次
var reg = /^a{2,4}$/;
console.log(reg.test("")); // false
console.log(reg.test("aa")); // true
console.log(reg.test("aaaaa")); // false
// 表单使用的例子
var reg = /^[a-zA-Z0-9_-]{6,16}$/;
console.log(reg.test("andy-red")); // true
console.log(reg.test("andy_red")); // true
console.log(reg.test("andy!007")); // false
// 只能输入 a-z 或者 A-Z 或者 0-9 _ - 并且必须在6位以上和16位一下
3.5 括号总结
1.大括号 量词符. 里面表示重复次数
2.中括号 字符集合。匹配方括号中的任意字符.
3.小括号 表示优先级
var reg = /^(abc){3}$/; // 它是让abcc重复三次
console.log(reg.test("abc")); // faslse
console.log(reg.test("abcabcabc")); // true
console.log(reg.test("abccc")); // fasle
var reg = /^(abc){3}$/; // 它是让abcc重复三次
console.log(reg.test("abc")); // faslse
console.log(reg.test("abcabcabc")); // true
console.log(reg.test("abccc")); // fasle
正则表达式在线测试: https://c.runoob.com/
3.6 预定义类

// 座机号码验证: 全国座机号码 两种格式: 010-12345678 或者 0530-1234567
// 正则里面的或者 符号 |
var reg = /^\d{3}-\d{8}|\d{4}-\d{7}$/; // 第一种写法
var reg2 = /^\d{3,4}-\d{7,8}$/; // 第二种写法
// 座机号码验证: 全国座机号码 两种格式: 010-12345678 或者 0530-1234567
// 正则里面的或者 符号 |
var reg = /^\d{3}-\d{8}|\d{4}-\d{7}$/; // 第一种写法
var reg2 = /^\d{3,4}-\d{7,8}$/; // 第二种写法
正则表达式的替换
字符串的 repace() 方法可以实现替换字符串操作,用来替换的参数可以是一个字符串或是一个正则表达式
stringObject.replace(regexp/substr,replacement)
- 第一个参数: 被替换的字符串 或者 正则表达式
- 第二个参数: 替换为的字符串
- 返回值是一个替换完毕的新字符串
例子: 一些网页中的敏感词的替换
btn.onclick = function () {
div.innerHTML = text.value.replace(/激情|gay/g, "**");
};
// 这个点击事件中把text 的 value值 中出现了 ‘激情’ ‘gay’ 的词 全部替换成 **
// 如果出现多个 敏感词 但是 repace 只能先替换最先的一个,所以要加上正则表达式的参数 g.g 代表全局匹配
btn.onclick = function () {
div.innerHTML = text.value.replace(/激情|gay/g, "**");
};
// 这个点击事件中把text 的 value值 中出现了 ‘激情’ ‘gay’ 的词 全部替换成 **
// 如果出现多个 敏感词 但是 repace 只能先替换最先的一个,所以要加上正则表达式的参数 g.g 代表全局匹配
正则表达式的参数
/表达式/[switch]
switch(也称为修饰符) 按照什么样的模式来匹配. 有三种值:
g : 全局匹配
i : 忽略大小写
gi: 全局匹配 + 回来大小写
一些正则表达式练习分析
验证是否为有效数字
/*
* 规则分析
* 1. 可能出现 + - 号 也可能不出现 [+-]?
* 2. 一位 0-9都可以, 多位首位不能是0 (\d|([1-9]\d+))
* 3. 小数部分可能有也可能没有, 一旦有后面必须有小数点+数字 (\.\d+)?
*/
let reg = /^[+-]?(\d|([1-9]\d+))(\.\d+)?$/;
/*
* 规则分析
* 1. 可能出现 + - 号 也可能不出现 [+-]?
* 2. 一位 0-9都可以, 多位首位不能是0 (\d|([1-9]\d+))
* 3. 小数部分可能有也可能没有, 一旦有后面必须有小数点+数字 (\.\d+)?
*/
let reg = /^[+-]?(\d|([1-9]\d+))(\.\d+)?$/;
验证密码
// 数字 字母 下划线
// 6 - 16 位
let reg = /^\w{6,16}$/;
// 数字 字母 下划线
// 6 - 16 位
let reg = /^\w{6,16}$/;
验证真实姓名
/*
* 1. 汉字 /^[\u4E00-\u9FA5]$/ \u4E00 代表 一
* 2. 名字长度 2 - 10 位 [\u4E00-\u9FA5]{2,10}
* 3. 可能有译名 ·汉字 例如: 尼古拉是·译名 (·[\u4E00-\u9FA5]{2,10}){0,2}
*/
let reg = /^[\u4E00-\u9FA5]{2,10}(·[\u4E00-\u9FA5]{2,10}){0,}$/;
/*
* 1. 汉字 /^[\u4E00-\u9FA5]$/ \u4E00 代表 一
* 2. 名字长度 2 - 10 位 [\u4E00-\u9FA5]{2,10}
* 3. 可能有译名 ·汉字 例如: 尼古拉是·译名 (·[\u4E00-\u9FA5]{2,10}){0,2}
*/
let reg = /^[\u4E00-\u9FA5]{2,10}(·[\u4E00-\u9FA5]{2,10}){0,}$/;
验证邮箱
let reg =
/^\w+((-\w+)|(\.\w+))*@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/;
// 1213563369@qq.com
// 分析
// \w+((-\w+)|(\.\w+))*
// 开头是 数字 字母 下划线 (一到多位)
// 还可以是 -数字 字母 下划线 或者是 .数字字母下划线 (整体零到多次)
// 例子: you-peng-tian 或者 you.peng.tian 或者 you-peng.tian
//=> 邮箱的名字: 由 数字 字母 下划线 - . 几部分组成 但是 - 和 . 不能连续出现也不能作为开始
// @[A-Za-z0-9]+
// @后面紧跟着 数字 字母 (1-多位)
// ((\.|-)[A-Za-z0-9]+)*
// 这部分是因为有邮箱 会出现 .com.cn 的可能
// \.[A-Za-z0-9]+
// 这部分才是匹配最后的 .com .cn .top ...
let reg =
/^\w+((-\w+)|(\.\w+))*@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/;
// 1213563369@qq.com
// 分析
// \w+((-\w+)|(\.\w+))*
// 开头是 数字 字母 下划线 (一到多位)
// 还可以是 -数字 字母 下划线 或者是 .数字字母下划线 (整体零到多次)
// 例子: you-peng-tian 或者 you.peng.tian 或者 you-peng.tian
//=> 邮箱的名字: 由 数字 字母 下划线 - . 几部分组成 但是 - 和 . 不能连续出现也不能作为开始
// @[A-Za-z0-9]+
// @后面紧跟着 数字 字母 (1-多位)
// ((\.|-)[A-Za-z0-9]+)*
// 这部分是因为有邮箱 会出现 .com.cn 的可能
// \.[A-Za-z0-9]+
// 这部分才是匹配最后的 .com .cn .top ...
验证身份证号码
/*
* 1. 一共18位
* 2. 最后一位可能是X
* 3. 身份证前六位: 代表省市县 (\d{6})
* 4. 中间八位: 年月日 (\d{4})年 (\d{2})月 (\d{2})日
* 5. 最后四位: 最后一位 (X或者数字) 倒数第二位 (偶数 女 奇数 男) 其余的是经过算法算出来的
*/
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(\d|X)$/;
/*
* 1. 一共18位
* 2. 最后一位可能是X
* 3. 身份证前六位: 代表省市县 (\d{6})
* 4. 中间八位: 年月日 (\d{4})年 (\d{2})月 (\d{2})日
* 5. 最后四位: 最后一位 (X或者数字) 倒数第二位 (偶数 女 奇数 男) 其余的是经过算法算出来的
*/
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(\d|X)$/;